Introduction to Cassandra DB (Part 2)

In part one, we looked at the very basics of Cassandra DB with an introduction to the Cassandra Query Language (CQL). In this part we are going to look at the architecture of a Cassandra DB setup, and examine each of its components - Cluster, Data Center, Rack, Server (Node), vNode.
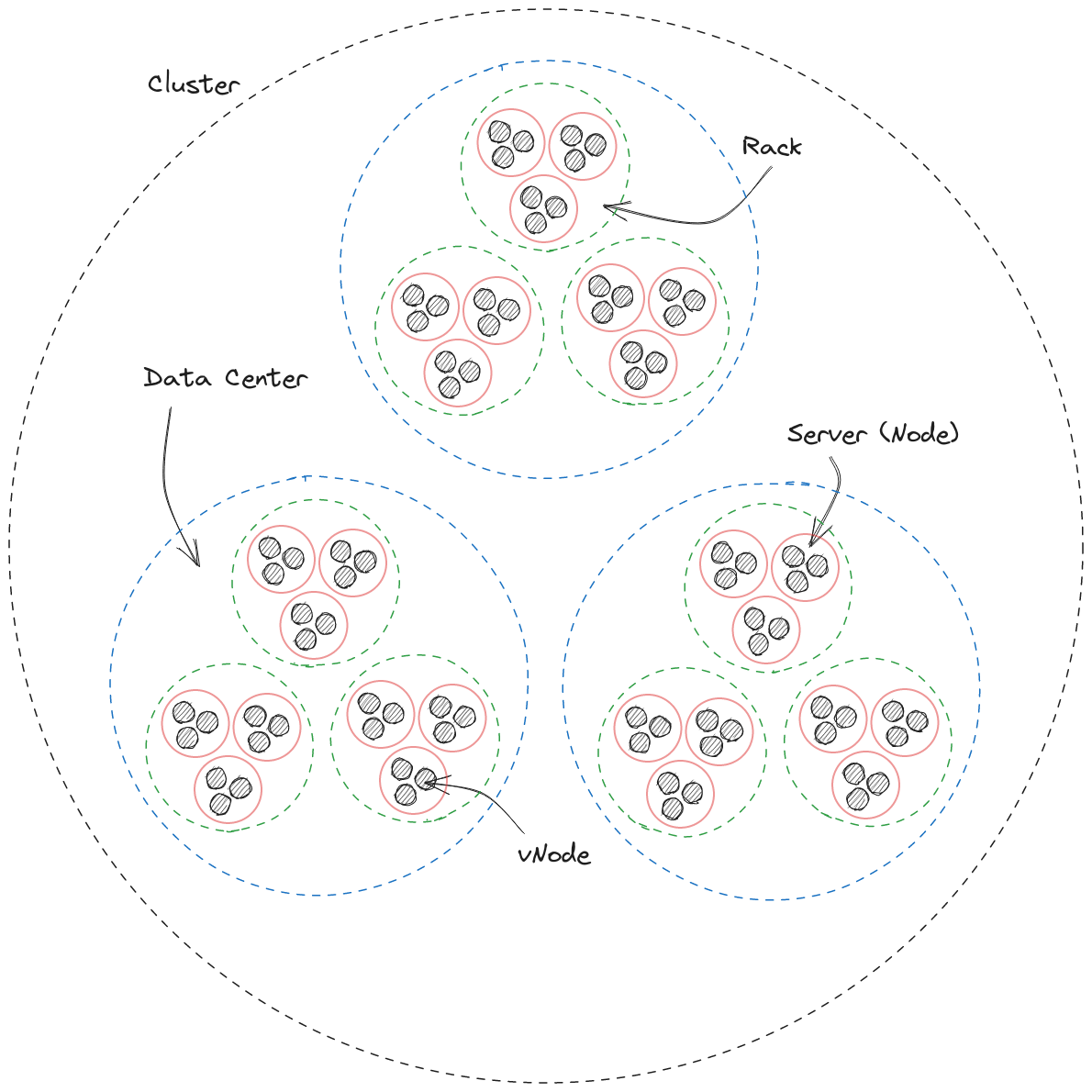
Cluster
Cassandra DB relies heavily on clusters to achieve its main value propositions: high availability, fault tolerance, and scalability. A Cassandra cluster is essentially a collection of nodes (individual server instances) that work together to store and provide access to large amounts of data in a distributed fashion. This distribution means that data is spread across multiple nodes, often residing on different physical servers or even different data centers, ensuring that the system remains robust against failures and can grow seamlessly by adding more nodes.
In the architecture of a Cassandra cluster, there's no master-slave differentiation or single point of failure. Instead, every node in the cluster is treated equally, and each node is responsible for a certain portion of the data. This approach, known as a peer-to-peer system, allows for continuous availability and resilience. As nodes communicate among each other, they consistently check the health and status of their peers using a protocol called the "Gossip Protocol." When it comes to data distribution, Cassandra employs consistent hashing, with the concept of 'token ranges' to decide which node should store which portion of the data. If a node becomes unavailable or experiences failure, other nodes in the cluster can still serve the data, ensuring uninterrupted access and high reliability. Furthermore, to cater to global deployments and disaster recovery, clusters can be set up across multiple geographical locations in what is termed as multi-datacenter configurations.
Data Center
In the context of Cassandra DB, data centers have a specific and pivotal role. While in general IT parlance, a data center refers to a physical facility housing servers and related infrastructure, within Cassandra's architecture, the term "data center" has a slightly different meaning. In Cassandra, a data center is a logical grouping of nodes (instances of Cassandra) that might or might not correspond to a physical data center. This distinction is vital for operational purposes, especially for ensuring high availability, fault tolerance, and efficient data access.
Cassandra's distributed nature means it is designed to run on multiple nodes spread across different geographical locations. When deploying Cassandra, it's common to spread nodes across multiple data centers to ensure resilience against regional failures or outages. This design means that even if one entire data center goes offline, the database can continue to operate using nodes from other data centers. Furthermore, Cassandra allows for tunable data consistency across these data centers, so developers can strike a balance between data consistency and latency. For instance, a global application can be set up to write data locally within a region for speed, but read data globally across multiple data centers for redundancy and availability. This multi-data center setup is crucial for businesses that require 24/7 uptime and cannot afford any regional outages or data loss. As such, understanding and effectively managing data centers within Cassandra's architecture is paramount for achieving optimal performance and reliability.
Rack
In the world of distributed databases, one of the most pressing concerns is data availability and resilience. Cassandra, a highly scalable NoSQL database, offers robust solutions to ensure that data remains accessible even in the face of hardware failures or network partitions. One of these solutions is the concept of 'Racks' in Cassandra's architecture.
A rack in Cassandra is essentially a logical set of nodes, typically designed to reflect the physical arrangement of nodes in a data center. The idea is to have Cassandra spread its replicas across different racks. Why? Imagine a scenario where a whole rack goes down due to power issues, hardware failures, or other unforeseen circumstances. If all replicas of your data were on that single rack, you'd face data unavailability. But by distributing replicas across multiple racks, Cassandra ensures that even if one rack goes down, other replicas in different racks can still serve client requests. This architectural design enhances fault tolerance and ensures high data availability.
Furthermore, when Cassandra decides where to place replicas, it uses the concept of 'NetworkTopologyStrategy', which takes into consideration both data centers and racks. This ensures that replicas are well-distributed, catering not only to rack-level failures but also potential data center outages. For anyone aiming for a truly resilient and fault-tolerant data storage solution, understanding and utilizing racks in Cassandra's topology is paramount.
Server
In the universe of distributed databases, the term 'server' often takes on a deeper significance beyond its traditional definition. Within the context of Cassandra, a server is typically referred to as a 'node', and each of these nodes is an independent entity with its own local storage and computational capabilities. A group of these nodes together forms what's known as a Cassandra cluster, and this cluster is the powerhouse behind the database's lauded horizontal scalability and high availability features.
Each node in the cluster has a specific role to play. They store data, serve client requests, and coordinate with each other to ensure data consistency and replication. Unlike monolithic databases where a single server might become a bottleneck, Cassandra's distributed nature ensures that data and read-write loads are distributed across multiple servers or nodes. This not only provides resilience against failures – as a failed node can be replaced without downtime – but also allows the database to linearly scale out by simply adding more nodes to the cluster. The decentralized nature of Cassandra means that there is no single point of failure, and every node in the cluster is treated equally without any specialized 'master' node. This architectural design ensures that the system remains operational and performant even as data grows or when facing high-throughput demands. For businesses or applications seeking scalable and fault-tolerant data solutions, understanding the role and significance of servers in Cassandra's framework is essential.
vNode
In Cassandra's distributed database architecture, the notion of partitioning and data distribution is of utmost importance. Earlier versions of Cassandra relied on a manual partitioning system where each node was assigned a range of token values, determining the portions of data the node was responsible for. While this system worked, it had its complexities, especially when adding or removing nodes. Enter Virtual Nodes (vnodes) – an innovation that greatly simplified and improved data distribution and management in Cassandra.
Virtual Nodes, or vnodes, divide each physical node in a Cassandra cluster into many smaller, logical units. Instead of a single token range, each physical node now contains multiple token ranges through its vnodes. This granular division serves multiple purposes. First, it ensures a more uniform data distribution across the cluster, as data gets spread across numerous vnodes on different physical nodes. Second, and perhaps more crucially, vnodes significantly simplify the process of scaling and repairing the cluster. When a new node is added, it takes over some vnodes from existing nodes, leading to a minimal data movement and a balanced data redistribution. Similarly, if a node fails or is removed, its vnodes get redistributed to the remaining nodes, ensuring data availability and resilience.
By abstracting the direct relationship between data and physical nodes, vnodes make cluster operations smoother and more efficient. For organizations leveraging Cassandra, understanding the power and potential of vnodes can lead to more optimal cluster management and enhanced system performance.
Summary
Hopefully this post has given you an understanding of the key components/terminology used within the CassandraDB ecosystem, and how they relate to each other.
At its core, Cassandra prioritizes data availability and resilience. By distributing data across various nodes, racks, and data centers, it ensures that businesses can access their vital data regardless of localized failures or outages.
In upcoming posts we will look at how CassandraDB goes about doing that.
Comments ()